Hi,
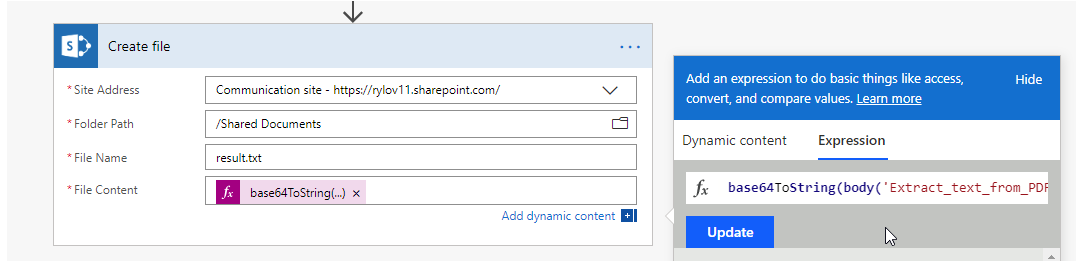
I would like to use the Extract Text from PDF document action in Plumsail Documents to extract text from PDF invoices we receive, and then capture relevant info from the text to save it to a SharePoint list.
However, when doing some tests with an ultra-simple flow (get the PDF from a SharePoint document library, get the content, process it), I'm not getting a clean HTML as shown in the documentation, but I get a "nonsensical" string.
Here's my flow:
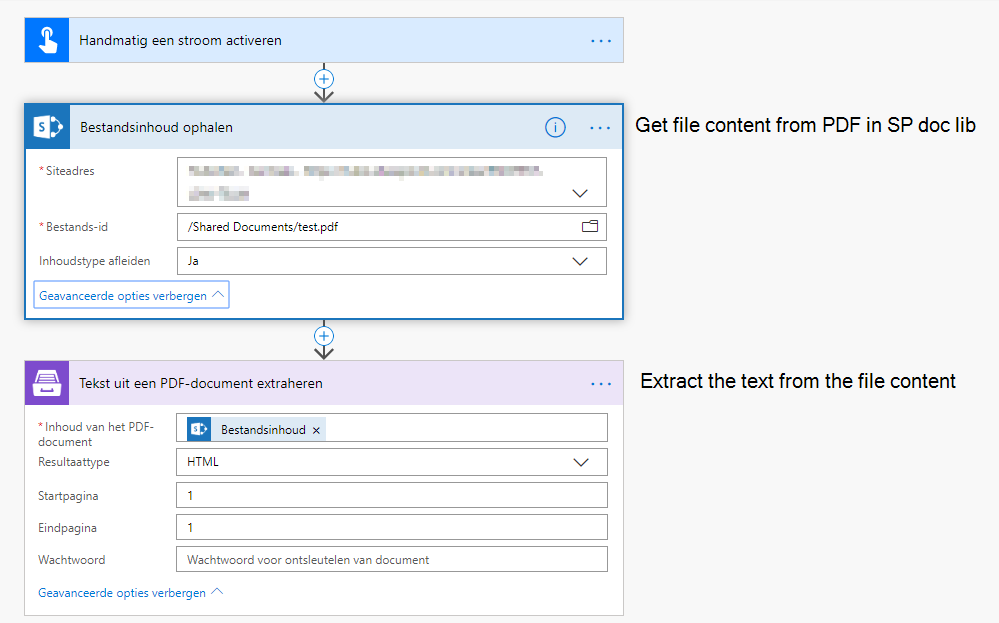
And this is the extracted text:
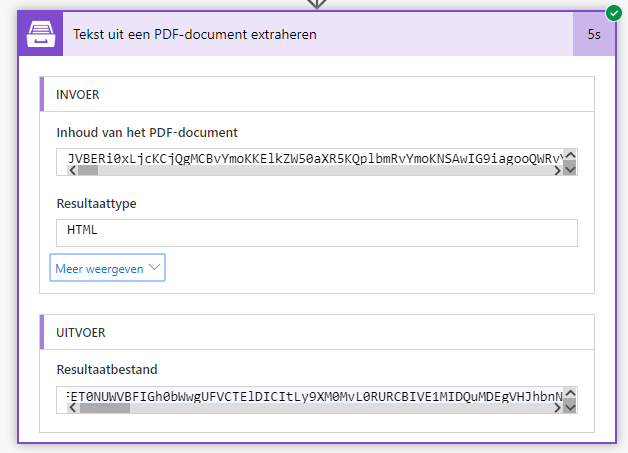
What am I doing wrong?
Thanks,
Filip